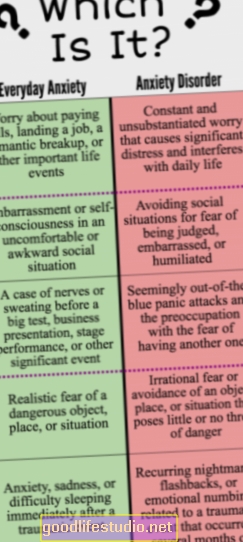
Đang phát triển: Điện thoại thông minh có thể đánh giá tâm trạng

Chương trình không phân tích những gì một người đang nói, mà là cách thức.
“Chúng tôi thực sự đã sử dụng bản ghi âm của các diễn viên đọc rõ ngày trong tháng - thực sự họ nói gì không quan trọng, đó là cách họ nói điều đó mà chúng tôi quan tâm,” Tiến sĩ, giáo sư Wendi Heinzelman cho biết kỹ thuật điện và máy tính.
Chương trình phân tích 12 đặc điểm của giọng nói, chẳng hạn như cao độ và âm lượng, để xác định một trong sáu cảm xúc từ bản ghi âm. Các nhà nghiên cứu cho biết nó đạt được độ chính xác 81%, một cải tiến đáng kể so với các nghiên cứu trước đó chỉ đạt được độ chính xác khoảng 55%.
Nghiên cứu đã được sử dụng để phát triển một nguyên mẫu của một ứng dụng hiển thị khuôn mặt vui hoặc buồn sau khi nó ghi lại và phân tích giọng nói của người dùng. Nó được xây dựng bởi một trong những sinh viên tốt nghiệp của Heinzelman, Na Yang, trong một kỳ thực tập mùa hè tại Microsoft Research.
“Nghiên cứu vẫn còn trong những ngày đầu,” Heinzelman thừa nhận, “nhưng có thể dễ dàng hình dung ra một ứng dụng phức tạp hơn có thể sử dụng công nghệ này cho mọi thứ, từ điều chỉnh màu sắc hiển thị trên điện thoại di động (điện thoại) đến phát nhạc phù hợp với cách bạn cảm giác sau khi ghi âm giọng nói của bạn. "
Heinzelman và nhóm của cô ấy đang hợp tác với các nhà tâm lý học Rochester, Tiến sĩ. Melissa Sturge-Apple và Patrick Davies, những người hiện đang nghiên cứu sự tương tác giữa thanh thiếu niên và cha mẹ của họ. “Một cách đáng tin cậy để phân loại cảm xúc có thể rất hữu ích trong nghiên cứu của chúng tôi,” Sturge-Apple nói. “Điều đó có nghĩa là một nhà nghiên cứu không cần phải lắng nghe các cuộc trò chuyện và nhập theo cách thủ công cảm xúc của những người khác nhau ở các giai đoạn khác nhau”.
Theo các nhà nghiên cứu, việc dạy máy tính hiểu được cảm xúc bắt đầu bằng việc nhận biết cách con người làm điều đó.
“Bạn có thể nghe thấy ai đó nói và nghĩ rằng‘ ồ, anh ta có vẻ tức giận. ”Nhưng điều gì khiến bạn nghĩ như vậy?” Sturge-Apple cho biết.
Cô giải thích rằng cảm xúc ảnh hưởng đến cách mọi người nói bằng cách thay đổi âm lượng, cao độ và thậm chí cả hài âm trong bài phát biểu của họ. “Chúng tôi không chú ý đến những tính năng này một cách riêng lẻ, chúng tôi chỉ đi tìm hiểu âm thanh tức giận là như thế nào - đặc biệt là đối với những người chúng tôi biết,” cô nói thêm.
Nhưng để một máy tính phân loại cảm xúc, nó cần phải hoạt động với các đại lượng có thể đo lường được. Vì vậy, các nhà nghiên cứu đã thiết lập 12 đặc điểm cụ thể trong giọng nói được đo lường trong mỗi bản ghi âm ở những khoảng thời gian ngắn. Sau đó, các nhà nghiên cứu phân loại từng đoạn ghi âm và sử dụng chúng để dạy cho chương trình máy tính biết âm thanh “buồn”, “vui”, “sợ hãi”, “ghê tởm” hoặc “trung tính”.
Sau đó, hệ thống phân tích các bản ghi âm mới và cố gắng xác định xem giọng nói trong bản ghi âm có miêu tả bất kỳ cảm xúc nào đã biết hay không. Nếu chương trình máy tính không thể quyết định giữa hai hay nhiều cảm xúc, nó chỉ để bản ghi đó không được phân loại.
“Chúng tôi muốn tự tin rằng khi máy tính cho rằng bài phát biểu được ghi lại phản ánh một cảm xúc cụ thể, thì rất có thể nó đang thực sự miêu tả cảm xúc này,” Heinzelman nói.
Nghiên cứu trước đây đã chỉ ra rằng hệ thống phân loại cảm xúc phụ thuộc nhiều vào người nói, có nghĩa là chúng hoạt động tốt hơn nhiều nếu hệ thống được huấn luyện bởi chính giọng nói mà nó sẽ phân tích. Sturge-Apple cho biết: “Điều này không phải là lý tưởng cho tình huống mà bạn muốn có thể chỉ chạy một thử nghiệm trên một nhóm người đang nói chuyện và tương tác, như phụ huynh và thanh thiếu niên mà chúng tôi làm việc cùng.
Các kết quả mới xác nhận phát hiện này. Nếu phân loại cảm xúc dựa trên giọng nói được sử dụng trên một giọng nói khác với giọng nói đã đào tạo hệ thống, độ chính xác giảm từ 81% xuống còn khoảng 30%. Các nhà nghiên cứu hiện đang tìm cách giảm thiểu tác động này bằng cách huấn luyện hệ thống bằng giọng nói ở cùng nhóm tuổi và cùng giới tính.
Heinzelman cho biết: “Vẫn còn những thách thức cần giải quyết nếu chúng tôi muốn sử dụng hệ thống này trong một môi trường giống với tình huống thực tế, nhưng chúng tôi biết rằng thuật toán mà chúng tôi đã phát triển hiệu quả hơn những nỗ lực trước đây.
Nguồn: Đại học Rochester